为什么有了AI,
你还被天天焊死在工位上?
Cursor、Claude Code 都有了,结果依然陷入赛博监工的低效内耗:
表面是AI全面赋能,底层逻辑却是你在给Agent做保姆。一整天都在喂Prompt对齐颗粒度 -> AI 链路崩盘 -> 手动重启 -> 循环填坑。拿着顶配模型,核心人效一点没释放。
模型侧单点能力溢出,
但在企业级落地的颗粒度上全面溃败。
核心痛点往往爆发在代码生成之后的执行、集成测试和部署。脱离本地沙盒,Agent根本不懂公司内部复杂的轮子和基建生态 -- 私有镜像源,GPU调度/服务部署平台,数据中心隔离等等
ssh to the edge node, kinit
--index-url, not public PyPI.
pyflyte run --remote, don’t run locally.
报错形态各异,但底层逻辑同源:
Agent 链路熔断,只能靠人工接盘兜底。
同样是"hdfs: command not found"。
Agent 判定环境阻塞,直接原地躺平。
但成熟的研发不会在这里死磕。直接检索内部知识库,切换到能access prod hdfs的Jump Box,测试运行代码。
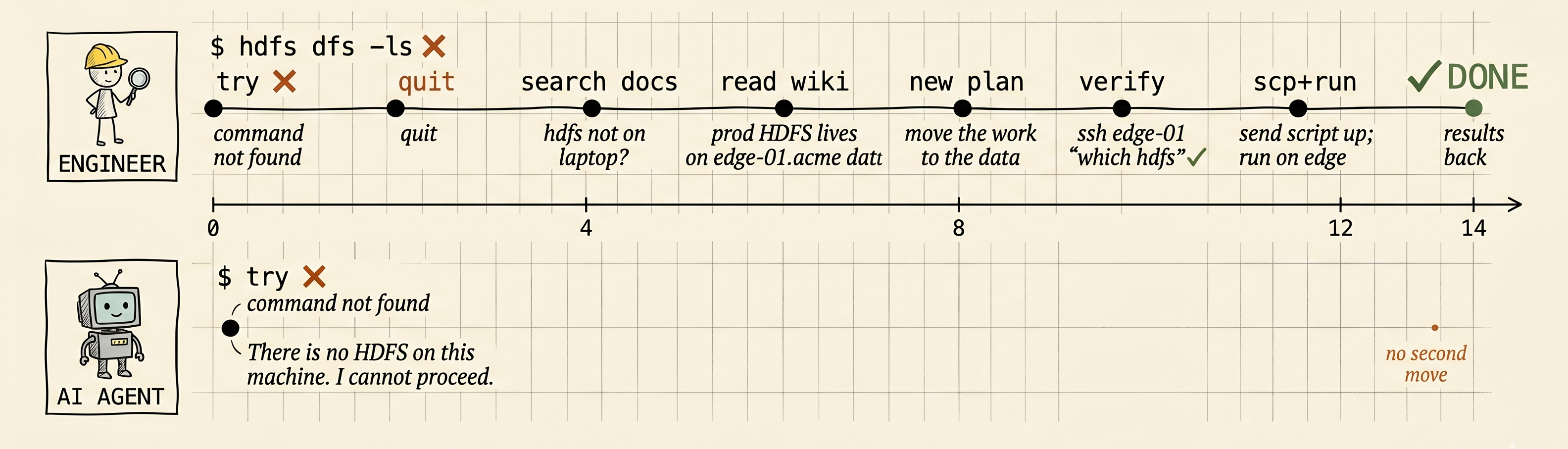
这并非模型参数量的代差,而是 AI 缺乏在复杂业务流中"找抓手"的工程能力。真正的 Retry 机制不是写个 for 循环做无意义的死锁重试,而是要在链路熔断时,通过查阅内部基建文档,重构执行路径(work-around),最终实现目标交付。
认知迭代:从"指令驱动"
升维到"终态对齐"
你一步步跟Agent保姆式微操的描述怎么做。
执行路径中任何一个节点的颗粒度没有对齐,整个 Workflow 直接崩溃,你被迫切回一线做消防员。
真正的解法是声明式架构:你只负责定义交付标准,底下的Agent自治打通链路。
遇到业务死锁自动触发内部重排(Recalculating),动态寻优,直到所有 Hard Gate 自动化校验点全部打满绿灯。
底层逻辑:"Done" 不能靠体感,必须拉齐硬性的 Hard Gate。
你用自然语言输入业务终态,系统里的虚拟 PM 会将其降维解析为自动化 Check 矩阵(跑 Shell 巡检、查库状态、聚合日志、断言报错)。底层的 Agent 矩阵在沙盒里怎么迭代不管,只要验收脚本没有 100% Pass,坚决阻断发布。
# end-state.yaml — auto-generated by the PM from your goal
checks:
# Case A — runs on the edge node, lands data in HDFS
— exec: ssh edge-01 'hdfs dfs -test -s /out/features/_SUCCESS' # exit 0
# Case B — the new feature actually runs end-to-end (proves deps resolved)
— exec: pytest tests/test_feature_pipeline.py -q # exit 0
# Case C — the agent must produce ${EXEC_ID} of a Flyte run on the cluster
— exec: flytectl get execution ${EXEC_ID} -o json | jq -e '.phase=="SUCCEEDED"' # exit 0
— exec: flytectl get logs ${EXEC_ID} | grep -q 'Training complete' # success signal
— exec: ! flytectl get logs ${EXEC_ID} | grep -qE 'ERROR|Traceback' # no errors你的 Prompt :没干完别停
大模型理解:赶紧找个借口罢工
它根本不会回头看。
内存池早就压缩过了。它纯粹是瞎焦虑。
但它连跑都没跑。
"环境"表示这锅我不背。
这就敢叫Done了。
指望一个单体 Agent 在几个小时的跨度里,既能做顶层架构设计,又做底层代码实现,还要兼顾 CI/CD 和 QA 验收。这在工程上极不科学,状态机和上下文不可避免会走向混沌。
把活儿甩给 SuperTeam,
醒来直接验收成果
Super Team 不是换个马甲的玄学 Prompt,
它是一套完备的 Harness(治理框架)系统:将各级 Agent 的权责边界隔离,固化状态机,引入客观的 Hard Gates,并配备能在执行偏离时强行拉回主线的项目大管家(Manager)。
以前,代码补全只是给个 snippet;Agent 只能包揽微型任务。下一个起飞点是"托管式交付"——人不在工位,系统一样能在后台把需求撸完。
从架构上看:你只需当一个甩手掌柜,
跟唯一的接口人(Product Manager)提需求
至于黑盒底层的专家矩阵怎么去拉齐会议、输出技术方案、拉分支、跑单元测试,遇到报错怎么做故障自愈——这原本都是耗费你大量研发带宽的低效劳动。
一旦全链路跑通,你直接验收 PR 产出物:无论是模型训练大盘的 AUC 提点,还是微服务集成测试的打平状态,抑或是数据仓库里已经清洗沉淀的表。
治理框架(Harness)
才是打通最后一公里的底层逻辑。
同样的底层大模型,套上不同的工程化外壳,交付质量天差地别。 精准的上下文路由、对抗式网关评估以及无状态的增量重启,才是将一个"玩具模型"升维为企业级可靠系统的核心壁垒——别再迷信写出冗长的花式 Prompt 了。
"Context 是极其昂贵的算力资源。"
在窗口里堆砌毫无关联的历史包袱,纯粹是在透支模型的 Reasoning 算力。 Super Team 采用渐进式按需下发(Progressive Disclosure)策略:每个 Node 只摄入与当前边界强相关的信息,拒绝全局污染。 Manager 采用 270 秒的 Tick 机制重读状态树,彻底掐断了 Context 随生命周期无限膨胀的恶性循环。
"自评天然带有"放水"倾向。"
模型一旦陷入自身的推理闭环,就会对自己的错误点头称是。 Evaluator(评估器)只盯契约(Contract)和最终产出— 严禁偷看生成器的思考过程。 这种设计在工程上保证了评估是"对抗式"的,而不是"复读机"式的,无需更换底层模型,也无需折腾 Prompt 工程。
"Context 堆积必然引发链路漂移。"
长生命周期产生的 Context 堆积会严重拉低系统可靠性。 生成器和评估器在每个增量节点都是全新的(Fresh)— 某个单元熔断,只重跑该单元,不搞全量重启。 固化的契约接管了 Context 的角色:精准承载新 Agent 复现或评判工作所需的全部上下文,不多不少。
参考来源 —Anthropic 工程团队:长生命周期 Agent 应用的治理框架设计
知识的两级分层架构
本地 Wiki沉淀项目侧专属的发现 — 架构坑位、未文档化的内部 API、测试范式、集成时的 Gotchas。全局 Wiki跟着 Owner 流转:工具链秘籍、公司规范、可复用的 Gate 脚本。 Explorer 在啃代码库前先读 Wiki,Curator 在每次 Session 收尾时自动同步。
知识如何复利
首次冷启动后,每一个 Session 都是"热乎"的。 Wiki 由Agent 自动化维护— Curator 写,Explorer 读,每一个项目都在做正向积累。原本每次会话都要重灌一遍的 Tribal Knowledge,沉淀成了永久资产。
一句话或一段话即可。无需输出技术方案 — 团队矩阵自治寻路。
全链路只需你下场这一次结合代码库现状的针对性追问 — 锁定 Scope、边界 Case、集成节点 — 直到 Spec 没有歧义。
动手写实现代码之前,先把验收脚本写好并评审通过。"Done" 必须是可量化 Check 的,不是靠体感。
由你负责 Review 和准入每个任务单元配独立的生成器和评估器。故障彻底隔离,不引发链路雪崩。上下文绝不跨单元堆积。
全自动执行目前市面上大部分 AI 工具,天花板就是底层模型本身。
下一代产品的护城河,在于模型周边的全栈工程化:持久化、容错机制、Memory、编排与对抗校验。
Super Team 用"搞系统"的工程思路把这件事拆开做:用 Contract 强对齐 Done 的标准,用专家化 Agent 做职责解耦,用共享内存确保上下文闭环。这才是从"代码助手"升维到"自动驾驶研发团队"的本质拐点——你不只是在用它,你是在向它派单。