In order to have a big picture about text classification, I read some review papers and took some notes as follows
This is a simple introduction to the world of text classification
Text classification is the task of classifying a document under a predefined category
1 Introduction
1.1 Problem
- People access information online while enormous information lacks organization which makes it difficult to manage
- Data for classification is of heterogeneous nature collected from multi-source and have different formats, different preferred vocabularies and different writing style —> automatic TC is essential
1.2 Application
since the inception of digital documents to manage the enormous amount of data available on the web
Information Extraction & Summarization
- Text Retrieval
- Question Answering
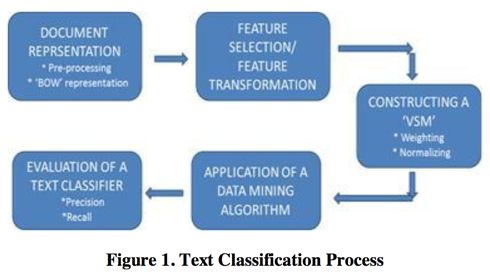
1.3 Steps involved in TC
- Document representation methods
- Feature selection methods
- Constructing a Vector Space Model (VSM)
- Data mining methods
- Evaluation technique used to carry out the results
Objective
- Single-label TC — A document is assigned to only one class
- TWO CLASS — “Binary class” problem
- N CLASS — “Multi-class” problem
- Multi-label TC — A document is assigned to more than one class
2 Process
2.1 Document Representation
It is the task of representing a given document in a form which is suitable for data mining system
Example — in the form of instances with a fixed number of attributes
- Bag-of-Words
Actually, many of them are not important for the learning task and their usage can substantially degrade performance
- So, to reduce the size of the feature space is imperative
- Approaches:
- Remove STOP WORDS — a list of common words that are useless
- Only keep the stemming word
2.2 Feature Selection or Feature Transformation
Applied to further reduce the dimensionality of the feature set by removing the irrelevant words
Advantages
- Smaller Dataset Size
- Considerable shrinking of the search space & lesser computational requirements
Goal
- Reduction of the curse of dimensionality to
- yield improved classification accuracy
- Reduce over fitting
- Reduction of the curse of dimensionality to
Methods
- Feature selection — An evaluation function that is applied to a single word to rank them by the score for feature selecting
- Document Frequentcy(DF)
- Term Frequency(TF)
- Mutual Informatin(MI)
- Information Gain(IG)
- Odds Ratio(OR)
- CHI-square statistic(CHI)
- Term Strength(TS)
- Feature transformation/Feature extraction
- Compacts the vocabulary based on feature concurrencies
- Example
- PCA(Principal Component Analysis)
- Feature selection — An evaluation function that is applied to a single word to rank them by the score for feature selecting
2.3 Constructing a Vector Space Model
Every document here is represented by a vector of N dimensionalities and the complete set of vectors for all documents under condideration is called a VSM
- Weighting the terms
- Methods like TFIDF
- Normalize the values of the weights before using the vectors
- The most necessary and important codition
2.4 Application of a data mining algorithm
- Bases
- Statistical Approaches — statistical method
- Machine Learning Method — various supervised&un-supervised techniques of ML
- DT (decision trees)
- NB (Naive-Bayes)
- Rule Induction
- NN (Neural Networks)
- KNN (K-nearest neighbors)
- SVM (Support Vector Machines)
2.5 Evaluation of a text classifier
Metric
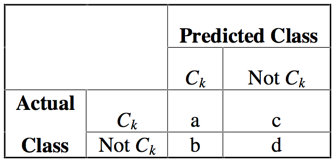
- Confusion Matrix
- Predictive accuracy — $\frac{a+d}{a+b+c+d}$
- Recall
- $\frac{a}{a+c} $
- The proportion of documents in category $C_k$ that are correctly predicted
Precision
- $\frac{a}{a+b}$
- The proportion of documents that are predicted as being in category $C_k$ that are actually in that category
Characteristics
- Each level of recall is associated with a level of precision
- Higher the recall, lower the precision, and vice versa
BEP(break-even point) — the point at which recall = precision
- BEP does not always exist
Therefore, it is common practice to combine Recall&Precision into a single measure of performance
- F1 Score — harmonic average of R&P
- For Binary class
- For multi-class
- Macro-average
- one confusion matrix per class
- and then performance measures are computed and these measures are averaged
- It measures weights all the classes, regardless of how many documents belong to it
- Micro-average
- only one contingency table is used for all the classes
- an average of all the classes is computed for each cell and the performance measures are obtained therein
- It measures weights all the documents, thus favoring performance on common classes
- Macro-average
Main Method in this Field
Unsupervised
Text embedding methods (SG, Paragraph Vector)
- Advantages
- Simple
- Scalable
- Effective
- Easy to tune and accommodate unlabeled data
Disadvantages
Yield inferior results — Compared to sophisticated deep learning architectures like CNN
- Cuz the deep neural networks fully leverage labeled information that is available for a task when learning the representations
Reason of the above
- Learn in a unsupervised way
- Not leverage the Labeled Information available for the task
- The Embedding learned are not particularly tuned for any task (But applicable to many different tasks)
Supervised
CNN
- Disadvantages
- Computational
- Need large amount of available labeled examples
- It requires exhaustive tuning of many parameters
Bag-of-words(BOW)&Bag-of-n-grams(BONG)
- Adavantages
- Simple
- Efficient
- Often Surprising Accurate
- For BONG, it preserve word order in short context
- Disadvantages
- Have little sense about the semantics of the words (distance between the words)
- Disadvantages of BOW
- Lose word order — different sentences—>same representation
- Disadvantages of BONG
- Data sparsity
- High dimensionality