
Writing code was always the easiest part of the job.
Writing code was always the easiest part of the job.

One of my wishes is that those dark trees,
So old and firm they scarcely show the breeze,
Were not, as ‘twere, the merest mask of gloom,
But stretched away onto the edge of doom.
Take a photo of coins and get the total value of them

This summer I worked as a Research Intern at Baidu USA, responsible for the development and research of the Apollo autonomous driving platform.
The rest of this post is organized as follows.
Leetcode每周碎碎念——参加了一个训练计划,每周输出一个Leetcode题目,除了有特别想总结的专题,通常会把内容都倒到这里。
这篇文章简略说明了下单调栈和单调双端队列的感性认知和经典应用。
TODO:本来想画画图啥的,但最近有点忙,以后有空再补上和详细说明吧
Parsing problems on leetcode are usually hard to write, hard to debug and variable for different situations, which makes it time-consuming. Sample problems might be the series of calculators. If you are trying to find a general, easy way (almost no annoying bugs after you finish it too!) to solve this kind of problems, then you should read this.
Basically this post introduce simple BNF and a easy-to-write Recursive Descent Parsing template to implement BNF.
There are many kinds of dynamic programming. DP over digit, just as its name shows, is doing dynamic programming over digits of a number. In this post, I will write a general template for this kind of problems.
First of all, we need to figure out what kind of problem it solves. The description of the problem is usually like:
Given a interval [lower, upper], find the number of all numbers $i$ that satisfy $f(i)$.
Here, the condition $f(i)$ is usually irrelated to the size of the number, but the composition of this number.
Sample Problems On Leetcode

This year is incredible! I believe I should be more prepared for the autumn job searching since it may become very difficult. One thing I guess I should do is to get more coding training for the interview process.
I believe it will be a long journey since currrently I only solve 65 out of 1200 problems. This is also the purpose of this post — to encourage & motivate myself by recording my journey on Leetcode — solving problems, attending weekly contests~
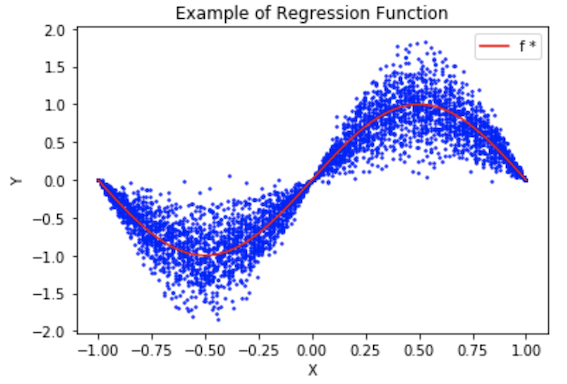
延续上一篇关于预测理论和ML的内容,本文旨在从数学角度理解和推导线性回归。
内容主要包括: