Predictive Text Embedding through Large-scale Heterogeneous Text Networks is an extension of the previous network embeddings algorithm – LINE, which utilize both labeled data and unlabeled data to learn a representation for text that has a strong predictive power for tasks like text classification
This artical is a simple review/note I did when learning this paper
- This artical is just a simple review/note from my report for this paper
- For more detailed and straightforward information with images, refer to
the report at the bottom of this page
1 Introduction
Motivation
Evaluation of existing methods
Unsupervised text embedding methods (SG, Paragraph Vector)
- Advantages
- Simple
- Scalable
- Effective
- Easy to tune and accommodate unlabeled data
- Disadvantages
- Yield inferior results — Compared to sophisticated deep learning architectures like CNN
- Cuz the deep neural networks fully leverage labeled information that is available for a task when learning the representations
- Yield inferior results — Compared to sophisticated deep learning architectures like CNN
- Advantages
Reasons for the above
- These text embedding methods learn in a unsupervised way
- Not leverage the labeled information available for the task
- The low dimensional representations learned are not particularly tuned for any task (But applicable to many different tasks)
Disadvantages of CNN
- It is Computational
- It assumes the there are large amount of available labeled examples
- It requires exhaustive tuning of many parameters — time-consuming for experts and infeasible for non-experts
Problem Definition
- Learn a representation of text that is optimized for a given text classification task — to have a strong predictive power
- Basic idea it to incorporate both the labeled and unlabeled information when learning the text embeddings
2 Related Work
2.1 Distributed Text Embedding
Supervised — only use labeled data
- Based on DNN like
- RNTNs (Recursive neural tensor networks)
- Each word <—> a low dimensional vector
- Apply the same tensor-based composition function over the sub-phrases/words in a parse tree to recursively learn the embeddings of the phrases
- CNNs (Convolutional neural networks)
- Word -> Vector
- Context Windows -> the same Convolutional kernel -> a max-pooling & fully connected layer
- RNTNs (Recursive neural tensor networks)
- if want to utilize unlabeled data
- Use indirect approaches like Pretrain the word embeddings with unsupervised approaches
Unsupervised
- Learn the embedding by utilizing word co-occurrences in the local context(Skip-gram) or at document level(Paragraph vectors)
2.2 Information Network Embedding
Representations learned through a heterogeneous text network
—> the problem of network/graph embedding
Classical graph embedding algorithms
- not applicable for embedding large-scale networks (millions of vertices & billions of edges)
Recent attempt to embed very large-scale networks
- Perozzi’s “DeepWalk”
- use truncated random walks on the networks
- only applicable for networks with binary edges
- The author’s previous model “LINE”
- Both of them are unsupervised and only handle homogeneous networks
- Perozzi’s “DeepWalk”
PTE — extends the LINE to deal with heterogeneous networks
3 Our Model — PTE (Predictive Text Embedding)
Charateristic
- semi-supervised
- utilize both labeled & unlabeled data
Process
- Labeled information & different levels of word co-occurrence information are first represented as a large-scale heterogeneous text network
- Then it is embedded into a low dimensional space through a principled&efficient algorithm
- This low dimensional embedding
- not only preserves the semantic closeness of words and documents
- but also has a strong predictive power for the particular task
Heterogeneous Text Network
Three types of bipartite networks
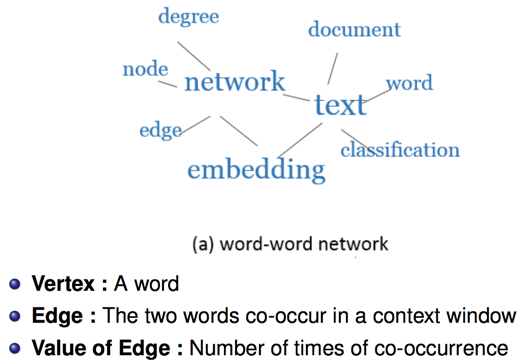
- Word-Word Network
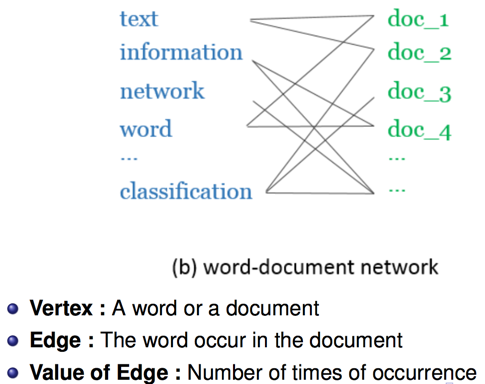
- Word-Document Network
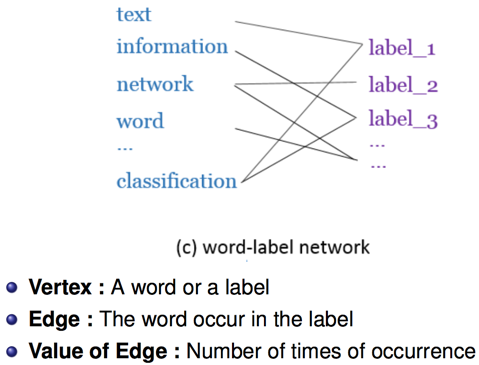
- Word-Label Network
Heterogeneous text network is the combination of the above
networks
1. Word-Word Network
2. Word-Document Network
3. Word-Label Network
Model
The probability of vi(vi ∈ VA) generated by vj(vj ∈ VB) is
the softmax result of their cos similarity :Represent a vertex’s conditional distribution by $p(\cdot|v_j)$
Make it close to its empirical distribution:
- λj – importance of the vertex – estimated by the degree
- $\hat{p}(v_i |v_j)$–estimatedby $w_{ij}$
Finally the overal objective function is the sum of the three text network’s objective functions
Approach
Optimized with SGD, using edge sampling & negative sampling
- Step
- Sample a edge according to its proportion of weight
- Sample K negative edges from a noise distribution $p_n(j)$
- Optimize it
Result
- Compared to recent supervised approaches based on CNN
- PTE is
- comparable
- More effective and more efficient
- Has fewer parameters to tune
- PTE is
4 Experiment
refer to the report below