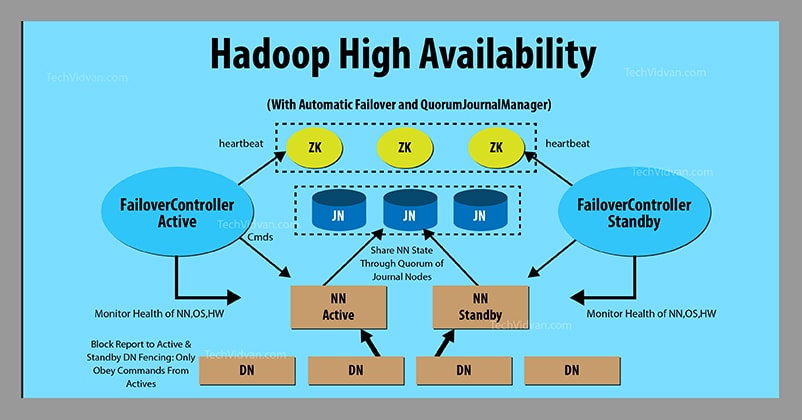
(图片引用自https://techvidvan.com/tutorials/hadoop-high-availability/)
这次暑假的实训是搭建一个HA的Hadoop集群,去年在University of Missouri的暑期项目搭载过spark和hdfs但只是在EC2上面的三个机子搭建,也没有实现HA
此次有实验室的十几个机子可以用,也引入了一些其它的概念像standby和zookeeper实现高可用性,同时因为配置需要,也更加深刻地理解了各个配置文件各项的含义
这个博文记录这次的配置以及遇到的问题和可能的解决方法
一、配置环境和配置版本
实验室机子物理位置、IP设置以及集群角色
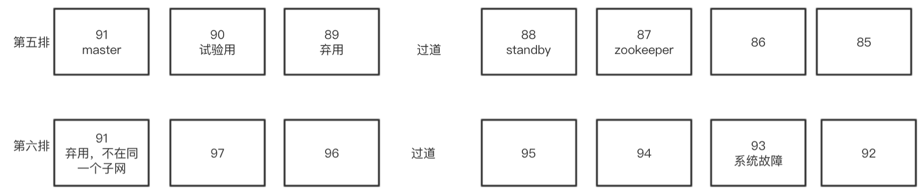
- 其中所有电脑的IP前缀为116.56.136
- 机子默认用户名字为pc(即~为/home/pc,此处需注意下文配置文件相应更改)
机器和角色分配矩阵
| NameNode | DataNode | JournalNode | ResourceManager | Zookeeper | ZKFC | gateway | |
|---|---|---|---|---|---|---|---|
| master | 1 | 1 | 1 | 1 | 1 | ||
| slave2 (standby) | 1 | 1 | 1 | 1 | 1 | ||
| slave3 | 1 | 1 | 1 | ||||
| slave4 | 1 | 1 | |||||
| slave5 | 1 | 1 | |||||
| slave6 | 1 | 1 | |||||
| slave7 | 1 | 1 | |||||
| slave8 | 1 | 1 | |||||
| slave9 | 1 | 1 | |||||
| slave10 | 1 | 1 |
配置版本
- Hadoop
- zookeeper
- 版本:3.5.4
- 下载地址:http://mirror.bit.edu.cn/apache/zookeeper/
二、配置过程
1. 配置ssh无密登陆
此项配置方便从master和standby无密码ssh到其它机子,为必须项
- 在master和standby上面使用
ssh_keygen -t rsa命令生成公钥(其储存在~/.ssh/id_rsa.pub内) - 使用cat命令将两个id_rsa.pub(公钥)放在同一个authorized_keys(pwd:
/.ssh)文件内,然后把authorized_keys覆盖到各个电脑的/.ssh同名文件- 可能步骤
- 可先将standby的id_rsa.pub传到master
- 使用
cat id_rsa.pub >> authorized_keys将master和standby的id_rsa.pub添加到master的authorized_key - 使用scp将master的authorized_keys传到其它所有机子的~.ssh/下面(若有机子没有则先用
ssh_keygen -t rsa生成 - 此处可写shell脚本for循环传送(亦方便设置完成后进行无密码登陆检查)(见附件)
- 可能步骤
2. 批量改hosts文件
此步骤的作用是为了方便集群管理以及实现配置文件可读性,此非必选项但是不应该跳过此步骤。
修改hosts文件即相当于给本地机子ip起别名,语法对应为 Name IP,比如master 116.56.136.91,本次配置其它所有机器名字为slave2-slave10
首先将master的hosts修改,然后使用脚本批量远程登录修改,需要步骤一作为基础。我们使用的脚本文件为send_host.sh 。具体的步骤为先使用scp把本机的hosts文件发送到目标电脑,然后使用cat覆盖原电脑的/etc/hosts文件,然后重启网络服务。
3. Hadoop HA 配置
a. 安装JAVA环境
此处可写shell脚本批量安装
yes | sudo apt-get updateyes | sudo apt-get upgradeyes | sudo apt-get install openjdk-8-jre-headlessyes | sudo apt-get install openjdk-8-jdk
b. 下载hadoop
此处选择直接安装到~目录下面
wget -P http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.13.3.tar.gztar -xf ~/hadoop-2.6.5.tar.gz -C ~mv hadoop-5.13.3 hadoop//改个名字比较方便
c. 修改hadoop配置文件
以下配置文件在~/hadoop/etc/hadoop下面,含义在文件里面注释说明
hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/pc/hadoop/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/pc/hadoop/data</value>
</property>
<!--定义NameServices逻辑名称,此处为lyx -->
<property> <name>dfs.nameservices</name> <value>lyx</value> </property>
<!--映射nameservices逻辑名称到namnode逻辑名称 nn1和nn2时自己起的两个有namenode的名字-->
<property> <name>dfs.ha.namenodes.lyx</name> <value>nn1,nn2</value> </property>
<!--映射namenode逻辑名称到真实主机名称(RPC) -->
<property> <name>dfs.namenode.rpc-address.lyx.nn1</name> <value>master:8020</value> </property>
<!--映射namenode逻辑名称到真实主机名称(RPC) -->
<property> <name>dfs.namenode.rpc-address.lyx.nn2</name> <value>slave2:8020</value> </property>
<!--映射namenode逻辑名称到真实主机名称(HTTP) -->
<property> <name>dfs.namenode.http-address.lyx.nn1</name> <value>master:50070</value> </property>
<!--映射namenode逻辑名称到真实主机名称(HTTP) -->
<property> <name>dfs.namenode.http-address.lyx.nn2</name> <value>slave2:50070</value> </property>
<!--配置JN集群位置信息及目录 -->
<property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://slave2:8485;slave3:8485;slave4:8485;slave5:8485;slave6:8485;slave7:8485;slave8:8485;slave9:8485;slave10:8485/lyx</value> </property> <!--配置故障迁移实现类,以下内容与ZOOKEEPER相关,先配置了等下不用改 -->
<property> <name>dfs.client.failover.proxy.provider.lyx</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property>
<!--指定切换方式为SSH免密钥方式 -->
<property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/pc/.ssh/id_rsa</value> </property>
<!--设置自动切换 -->
<property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property>
<!--配置journalnode edits文件位置 -->
<property> <name>dfs.journalnode.edits.dir</name> <value>/home/pc/hadoop/current/journal/data</value> </property>
<property>
<name>ha.zookeeper.quorum</name> <value>master:2181,slave2:2181,slave3:2181</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>core-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/pc/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://lyx</value>
</property>
<!--设置zookeeper的ip和端口 -->
<property>
<name>ha.zookeeper.quorum</name> <value>master:2181,slave2:2181,slave3:2181</value>
</property>
</configuration>yarn-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanger.zk-address</name>
<value>master:2181,slave2:2181,slave3:2181</value>
</property>
</configuration>hadoop-env.sh后面添加以下语句
1 | export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64 |
在该目录下新建slaves文件,输入slave
1
2
3
4
5
6
7
8
9slave2
slave3
slave4
slave5
slave6
slave7
slave8
slave9
slave10同目录新建master文件,输入master
d. 环境变量
在/etc/profile里面添加以下语句,并用source /etc/profile运行刷新
1 | #Hadoop |
e. SLAVES上面安装配置Hadoop
- 将master上面的hadoop文件夹打包,用shell脚本写个for循环scp到其它所有slave
scp -r /home/pc/hadoop root@slave${i}:/home/pc/hadoop
- 解压缩,命令同master
- 重复上一节的环境变量设置
f. 初始化和启动hadoop
- 启动除master之外的节点的journalNode
- slave2-slave10执行
hadoop-daemon.sh start journalnode
- slave2-slave10执行
- master上面运行
~/hadoop/etc/hadoop/hadoop-env.sh设置hadoop环境变量 - 格式化master的namenode
hdfs namenode -format - 启动master的namenode
hadoop-daemon.sh start namenode - 将master的fsimage同步到slave2(standby):
- 在slave2(standby)上执行
hdfs namenode -bootstrapStandby
- 在slave2(standby)上执行
- 在master上面执行
start-dfs.sh开启所有节点
- 此处需注意默认两个namenode都是standby的状态,可运行以下命令进行强行切换
hdfs haadmin -transitionToActive --forceactive nn1- nn1即是我们在hdfs-site.xml里面设置的master的名字
此时若在master使用hadoop-daemon.sh stop namenode 强行关闭namenode会发现slave2无法切换到active状态(但可以使用上述haadmin命令进行强行切换)————需要配置zookeeper进行自动切换
其它说明
- 在master上网页访问master:80070可观察namenode和datanode状态
- 使用jps进程可以看到各节点当前进程:
- master:
- namenode
- slave2(standby):
- namenode
- datanode
- journalnode
- slave3-slave10:
- datanode
- journalnode
- master:
4. Zookeeper安装配置启动
安装配置
解压
tar -zxvf zookeeper-3.5.4.tar.gz -C ~重命名
mv zookeeper-3.5.4 zookeeper修改环境变量
vim /etc/profile1
2
3#zookeeper
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin刷新配置
source /etc/profile修改zookeeper的配置文件:
cd ~/zookeeper/confmv zoo_sample.cfg zoo.cfg- 打开此文件并修改两处
dataDir=/home/pc/zookeeper/data- 在末尾添加此处即选择三个节点安装zookeeper,本此配置使用了master,slave2-3三个节点,上面为其对应ip
1
2
3server.0=116.56.136.91:2888:3888
server.1=116.56.136.88:2888:3888
server.2=116.56.136.87:2888:3888
服务器标示修改
- 在zookeeper里面
mkdir ~/zookeeper/data - 在data里面新建文件myid,并填写内容为0
- 在zookeeper里面
将zookeeper打包弄到其它两个机子重复以上过程,注意对应的myid文件要分别改为1和2
启动
- 三台机子运行
zkServer.sh start命令启动 - jps可看到QuorumPeerMain进程
zkServer.sh start可以查看状态- 三个节点随机一个为leader其它为follower
4.Hadoop HA启动
- 停止所有服务
stop-dfs.sh - 在一个namenode上执行
hdfs zkfc -formatZK格式化zk - 重启
start-dfs.sh
此时通过http访问端口可以看到其中一个节点为active,另一个为standby,若在active节点上使用命令’hadoop-daemon.sh stop namenode干掉namenode,可以看到原先的standby自动变成active
- 启动ResourceManage
高版本的hadoop使用yarn模块统一管理,所以只需要在master开启yarn就行了start-yarn.sh
之后可以在master上jps看到ResourceManager,在其它机器看到nodeManager进程
至于Hadoop的RM的http访问在8088端口,即master:8088