What it solves for
Parsing problems on leetcode are usually hard to write, hard to debug and variable for different situations, which makes it time-consuming. Sample problems might be the series of calculators. If you are trying to find a general, easy way (almost no annoying bugs after you finish it too!) to solve this kind of problems, then you should read this.
Basically this post introduce simple BNF and a easy-to-write Recursive Descent Parsing template to implement BNF.
Sample Problems on Leetcode
Backus-Naur Form (BNF) Grammar
Wiki defines BNF as a notation technique for context-free grammars, often used to describe the syntax of languages such as computer programming languages. Please don’t be deterred by this abstract concept. It will be quite clear and simple after walking through an example. (If you have taken compiler class before, you can skip this chapter…)
A basic example might be Basic Calculator II, which asks to write a calculator for expression only with +, -, *, / and positive numbers. The BNF that describes the syntax of such an expression looks like this:
1 | <Expr> ::= <Term> {(+|-) <Term>} |
Let me explain the symbols used here. Usually a BNF is consisted of the following:
Non-terminals: names enclosed in<,>like<Number>, which can generate a kind of expression — usually consisting of differentterminalsandnon-terminalTerminals: characters like+,-,*,/,1,2, …, which cannot generate into another expression.::=: Just like an assignment, interpreted as “is defined as“. It describes that the left-hand-sideNon-terminalswill generate an expression in the right-hand-side. For each statement like this, we call it a production.|: ANon-terminalsmight generate into different expressions, you can use|to separate them, which means OR. Note that it has the lowest priority, so if you want to expression an or between two small items, use()to group them.{}: Items existing 0 or more times are enclosed in curly brackets[]: Optional items enclosed in square brackets
So how is this BNF related to the calculator I described above?
Well, you can use this BNF, specifically, the <Expr> non-terminal to generate all legal expressions of this calculator. Let me explain each production below:
<Expr> ::= <Term> {(+|-) <Term>}: An<Expr>might be one or multiple<Term>concatenated by+or-.<Term> ::= <Number> {(*|/) <Number>}: Similarly, each<Term>is either a<Number>or muliple<Numbere>concatenated by*or/.- Note that we distinguish
<Expr>and<Term>because the priority of*and/is higher than+and-, which helps to calculate correctly.
- Note that we distinguish
<Number> ::= <Digit>{<Digit>}: a<Number>is consisting of one or more<Digit>.<Digit> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9: this one is obviouse, a<Digit>is just a digit.
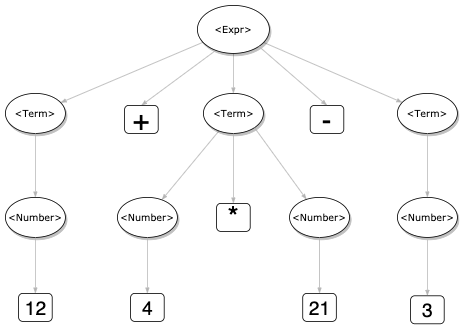
An example — 12 + 4 * 21 - 3 can be described as the BNF tree below:
Converting BNF to C++ code — Recursive Descent Parsing
There are many ways to implement a BNF parser depending on the complexity of the grammar. Usually for problems on leetcode, a simplest Predictive Recursive Descent Parser. Note that it is only possible for the class of LL(k) grammars. Here, LL(k) means you can decide which production to use by examining only the next k tokens of input. Usually a LL(1) will be enough.
For example, you want to parse a term using <Term> ::= <Number> | (<Expr>). You can look ahead the next token (LL(1)) to decide whether this <Term> is intepreted as a <Number> or an <Expr>
- if the next token is a digit like
1,2, then you know it’s a<Number>; - if the next token is a left parenthesis
(, then you know it’s a<Expr>; - Otherwise you should raise an error…
Still, take the Basic Calculator II as an example. The Algorithm is very simple, consisting of the following parts/steps:
- A global variable of type string —
input— stores the input and another global variable stores the current index —idx— of the input. - A
lookaheadfunction reads the next token but NOT incrementidx. - A
getcharfunction reads the next token AND incrementidx. - Write a function for each
Non-terminal, which determines which production to use, consume the input string and calculate the result.- For
{}symbols, remember it means that items inside exists 0 or more times.- We use a while loop — fisrt use
lookaheadto check whether the next token is the beginning of the item inside[]. - If it is, we recursively call the corresponding function.
- We use a while loop — fisrt use
- For
[]symbols, just use an if statement to check.
- For
1 | class Solution { |
More examples and solution code using BNF
The following are all problems on Leetcode. I will provide the BNF and my code.
Ternary Expression Parser
If you want to practice the algorithm above, you would better try this simple one first.
The problem is described as:
Given a string representing arbitrarily nested ternary expressions, calculate the result of the expression. You can always assume that the given expression is valid and only consists of digits
0-9,?,:,TandF(TandFrepresent True and False respectively).
Example inputs and outputs:
- Example 1:
2
3
Output: "2"
Explanation: If true, then result is 2; otherwise result is 3.
- Example 2:
2
3
4
5
6
Output: "F"
Explanation: The conditional expressions group right-to-left. Using parenthesis, it is read/evaluated as:
"(T ? (T ? F : 5) : 3)" "(T ? (T ? F : 5) : 3)"
-> "(T ? F : 3)" or -> "(T ? F : 5)"
-> "F" -> "F"
- Solution:
1 | class Solution { |
Basic Calculator III
A calculator with +-*/ and ().
- Very similar to the example in the tutorial, except that there is
().- Remember in the previous example,
Termis interpreted as differentNumber? Now it can also be anotherExprwith()— I call itFactor, which is either aNumberor anExpr.
- Remember in the previous example,
- Actually I extend it so that it can solve negative number as well ! — Note the optional
+/-at the begining ofExprandFactor Since that are
()in the input string (also a keyword of BNF), I use\(to mean that it is a true(charater in the input string.Solution
1 | class Solution { |
Parse Lisp Expression
Here comes a much harder one. Details of problem description please refer to leetcode.
There are several important points to note:
- In the previous example, every token is just a single character. It doesn’t work for most grammar.
- For example, without seeing the whole word, you will not a token starting with
wis just a variable name or the keywordwhilein a programming language like c++. - But this won’t make things complicated. You just need to write a function to split input string into an array of tokens according to delimiter like space — usually including keywords in that grammar too.
- For example, without seeing the whole word, you will not a token starting with
- LL(1) is not sufficient here, LL(2) is needed. But this is also a easy thing. You just need to provide an offset parameter in the
lookaheadfunction so that you can “LOOK INTO” the next next token.- Example might be
Expr ::= Let | Addmult | Term. - Say the input string is
(add 1 2)—["(", "add", "1", "2", ")"]as tokens — you will not know it should be intepreted into aAddmultor aLetif you just know the next token is(.
- Example might be
1 | class Solution { |
Basic Calculator IV
- The hardest one!
- No new contents. You should be able to figure it ourt if you have finished the previous example…
1 | class Solution { |