
Writing code was always the easiest part of the job.
Two years ago I was on Copilot autocomplete. A year ago I switched to Cursor. The last six months it’s been Claude Code. Most of my friends followed the same path.
Every one of us would tell you the tools are good. Autocomplete is sharp. A prototype goes from idea to running in an hour. Even hairy modules get drafted by the agent in one pass.
And every one of us is still extremely busy everyday. After a few retros I had to admit the obvious: this wasn’t a tool problem. It was a workflow problem.
AI writes a full prototype in a night. Cursor can complete an entire module from a function signature. Then what exactly is it making faster?
Writing code is the easiest part of the workflow
The misconception I had to break first: AI is faster at writing code is not the same statement as AI is faster at engineering.
AI is genuinely good at code now. Last week I asked Claude Code to support exporting Torch Package in a ML training library. Ten minutes for something that would have taken me two hours, unit tests included. Design isn’t bad either. Hand it a PRD and it’ll push back on edge cases and compatibility issues I would’ve missed in a first pass.
But code and design are not what fills my day.
Honest time breakdown for one normal week: about 30% writing or modifying code. About 15% in meetings, scoping, writing docs. The other 55% is wrestling with internal infra.
That 55% looks like this. Design phase: digging through internal wiki for how a neighboring team handled a similar ranking problem three years ago. Scrolling Slack for the RCA from last quarter’s outage. Hunting through Confluence for the on-call runbook for some upstream service. Context is scattered across roughly seven internal tools and no agent can search across them.
After the code is written, the rest is heavier. Running e2e tests in the stage environment because they refuse to run locally on a poor Mac without GPU. Hitting prod with a sample query through Bastion plus a temporary SSO to confirm an assumption. Submitting a model to the H100 cluster, watching the metrics 40 minutes later, finding AUC short of target, going back to feature engineering, resubmitting, waiting another 40. Fighting a build system written in 2018, six flags, none of them obviously named. Watching P99 on a deploy canary’s monitoring dashboard for an hour. On-call: PagerDuty fires, log trawl, figuring out which upstream service changed a contract.
Every single one of these steps depends on an internal platform, tool, or wiki. And most of those environments are not AI-aware. Cursor cannot read my monitoring dashboard. Claude Code does not know how our internal deploy tool works. An agent that wants to submit an ML training job first has to learn an internal CLI whose own documentation isn’t AI-readable.
So every step either gets done by hand, or I burn human cycles feeding context to the AI.
I’ve started calling this capability enterprise execution: the ability to navigate the complex infra of a real company — its platforms, tools, wikis, and processes.
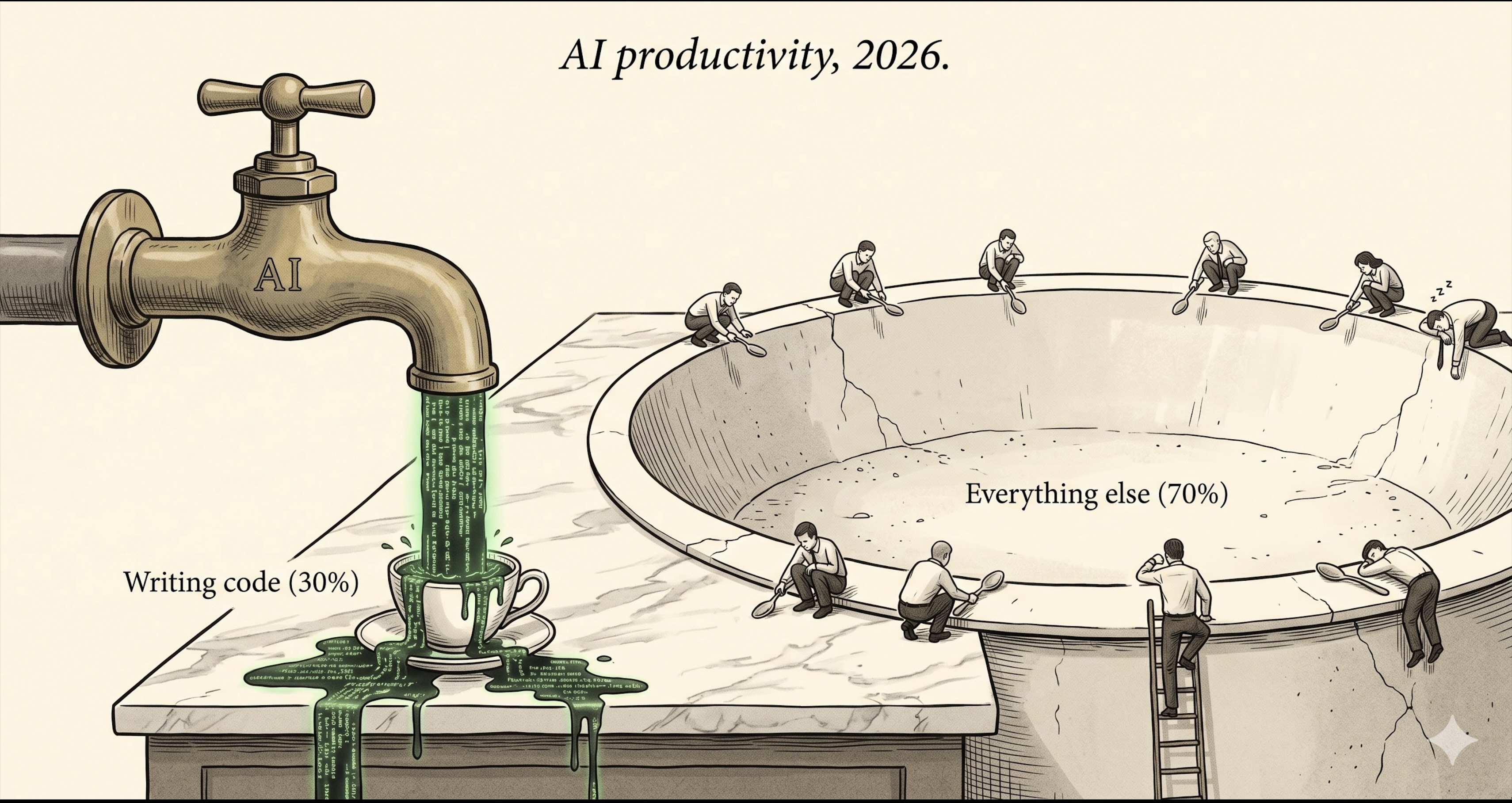
Once you see it, it’s obvious. AI accelerates the writing-code stage. That stage is the thinnest slice of the actual workday. Enterprise execution is the real bottleneck, and AI’s coverage there is close to zero. METR’s forty-point gap is not a mystery; it’s the perceptual error of mistaking coding feels fast for the whole workflow is fast.
The whole industry has been pushing LLMs through the rest of the workflow
Many people are dismissive about every new Anthropic concept that shipped in the past 2 years. Prompt Engineering. MCP. Agent Skills. Plugin. Hooks. Harness. The standard reaction is some version of “this is markdown reskinned.“ On Twitter the dunks come in waves: “thin wrappers around subtasks,” “MCP feels like wearing diapers”.
I held that view for a while too.
Then writing the previous section made me see what the dismissive view misses. There’s a clear through-line. From prompt to harness, every supposedly markdown-packaged concept is closing a specific gap in the workflow. Every step pushes the LLM further out from being a code-writing assistant into being a worker.
Let me string the line up.
Stage 1: Prompt Engineering (first half of 2024)
The battleground was writing prompts. Chain-of-thought, few-shot, role-play, output-format constraints. Everyone believed prompt is the interface: write it well and the model performs. WeChat newsletters had a “100 prompt patterns” listicle every other week.
Capability added: the LLM understands what you want.
Limit: a great prompt can still only show the model what’s in this turn’s input. Long context gets truncated, drowned in noise. Every new conversation starts blank. The model doesn’t know your codebase, your stack, or where you were debugging yesterday.
Stage 2: Context Engineering (second half of 2024)
Within a quarter, people realized “write a good prompt” was the wrong question. The hard part is putting the right information in front of the AI at the right time.
The patterns spread fast. AGENTS.md / CLAUDE.md so the AI starts a session knowing project layout, coding conventions, and how to run tests. RAG so it can pull from a knowledge base on demand. Compression and summarization, so a 100k-token meeting transcript becomes a 5k-token brief. Cross-session memory, so preferences and lessons learned persist.
Capability added: the right context lands in front of the model without depending on a single perfect prompt.
Limit: the AI is still a passive receiver. It answers your questions. It doesn’t do anything.
Stage 3: MCP (November 2024, hands and feet)
In November 2024 Anthropic released the Model Context Protocol. Before MCP, every team giving an LLM external tools wrote its own version of ReAct. Cursor had one. Claude had one. LangChain had a third.
MCP unified the calling convention into an open protocol. Write a server once, every MCP-aware client can call it.
From this step on, the LLM does things. Book a flight. Query the web. Run a SQL query. Read a database. Edit a file.
Capability added: the LLM produces external side effects.
Stage 4: Skills (H2 2025, codified methodology)
Anthropic shipped Agent Skills in October 2025. My first reaction was the predictable one: this is just markdown plus YAML, I already have a ~/prompts/ folder.
Two months in I changed my mind.
What Skills actually solves is reuse. Writing down a method is easy. Writing it down such that everyone in the org can keep calling it is the hard part. A Skill encodes “a specific task done a specific way.” Write a plugin against our internal framework is a Skill. Submit an ML training job to the GPU cluster is a Skill. Once it’s written down, every person and every agent calls it. Nobody re-derives.
The difference from prompts is what they live in: prompts live one session, skills live the organization.
Capability added: the LLM does a specific thing correctly. Not improvising each time. Following the codified method.
Stage 5: Plugin / Hooks / Subagent / Teams (late 2025 to early 2026, staying on rails)
This batch piles up a lot of concepts, but they all answer the same question: how do you keep an LLM on rails through a long session?
Past about 20 minutes, a Claude Code session starts to drift. Constraints set early get forgotten. Output slowly diverges from the spec. This is a real engineering problem; you cannot wave it away with more markdown.
Plugins bundle skills, agents, hooks, and commands. Hooks intercept the agent at exit and re-inject the goal. Subagents and Teams let multiple agents collaborate in isolated contexts.
The cleanest data point that this direction is right is Cognition’s reversal. In June 2025 they published Don’t Build Multi-Agents, dunking hard on multi-agent architecture. Ten months later, in April 2026, they shipped Multi-agents Working, conceding that narrow multi-agent does work: “let agents contribute intelligence, but keep writes single-threaded.” A team that famous publicly reversing a take in under a year is a strong signal that the underlying problem is real.
Capability added: the LLM stays stable. Demo time goes from 20 minutes to 20 hours.
Stage 6: Harness (early 2026, the engineering ring becomes a named thing)
In early 2026 a new consensus crystallized. LangChain’s March post The Anatomy of an Agent Harness gave it a name: Agent = Model + Harness.
What’s a harness? Everything outside the model. Tools, context management, memory, control flow, error recovery, state persistence.
The implication is sharp: the model is roughly good enough. What’s missing is the engineering wrapped around it.
There’s been a flood of specific harness work in the last few months. Geoffrey Huntley named the Ralph Loop, after the dim Simpsons character Ralph Wiggum. One line of bash:
1 | while :; do cat PROMPT.md | claude-code ; done |
Each iteration restarts the context and re-injects the goal. Huntley’s framing has stuck with me: “deterministic stupidity is a more reliable answer than non-deterministic cleverness.” An agent runs for half a day without drifting, not because it’s smart. Because the harness pins it down.
In the same family: Hooks (catch the agent at exit, re-inject the goal). Multi-agent teams (isolated contexts, contracts between agents, separate the generator from the evaluator).
These are all variations on one move. Take model + tools + context + memory + control flow, treat it as a single engineered system, and ship that. When one model can’t get there alone, let the engineering catch it.
Stack those six stages up. None of this is markdown reskinning. Each step closes a real workflow gap and pushes AI further out into the rest of the job.
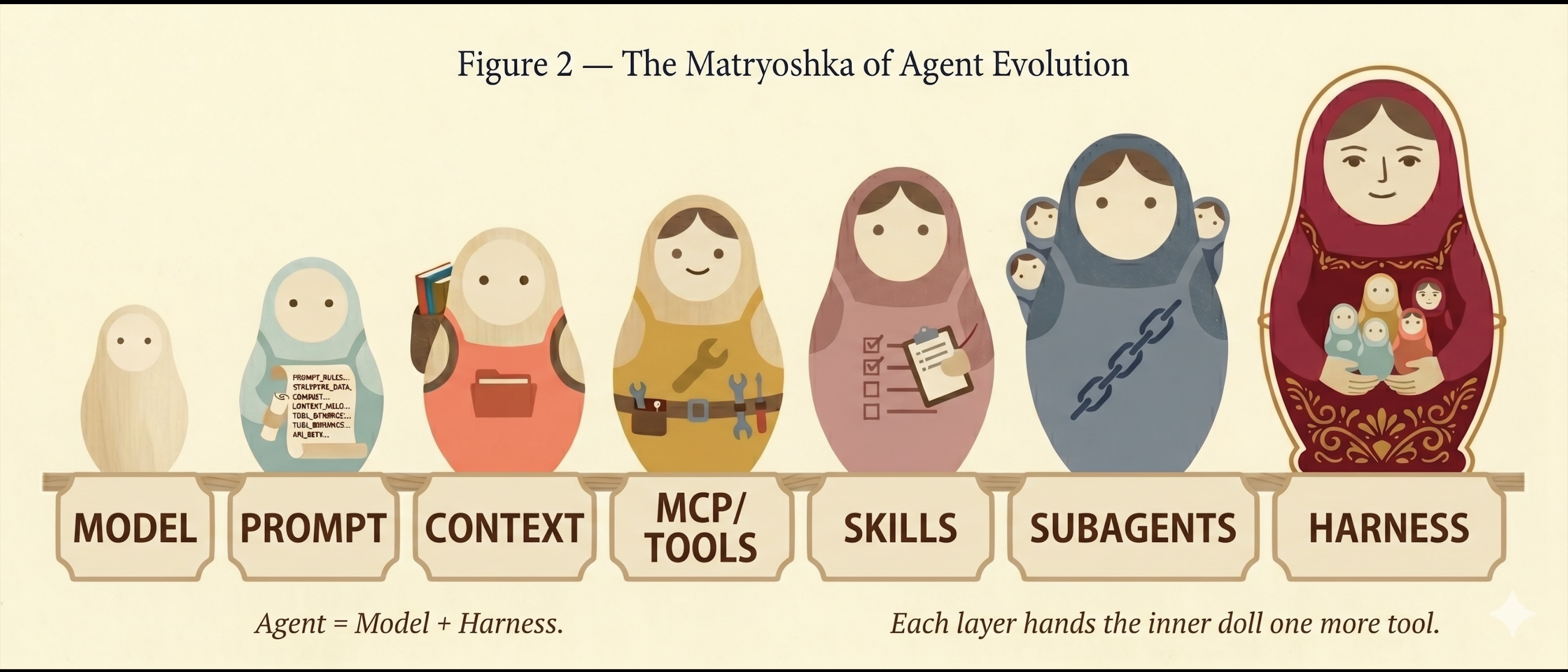
The catch: we made it to the harness era. We did not make it to the end.
The enterprise-execution last mile is still not covered
A harness that runs eight hours is a demo. Demos do not cover enterprise execution at a real company. ML training platforms. Internal deploy tools. Databases. Stage environments. Telemetry. Wikis scattered across seven different tools.
Three specific gaps.
First, coverage. There’s a number I’ve been quoting since I saw it earlier this year, originally from a Chinese-language industry post in 闲谈数字化: 93% of enterprise AI agent projects stall between POC and production. Ninety-three percent.
That sounds like hyperbole until you’ve worked at a big company. Internal infra is roughly a thousand chains. Build, deploy, monitoring, alerting, training, serving, data warehouse, experimentation, on-call, incident response. Each is its own stack. An agent that wants to drive a workflow end-to-end breaks the moment any single link is not AI-aware. 1% of tools missing means 100% of the workflow fails.
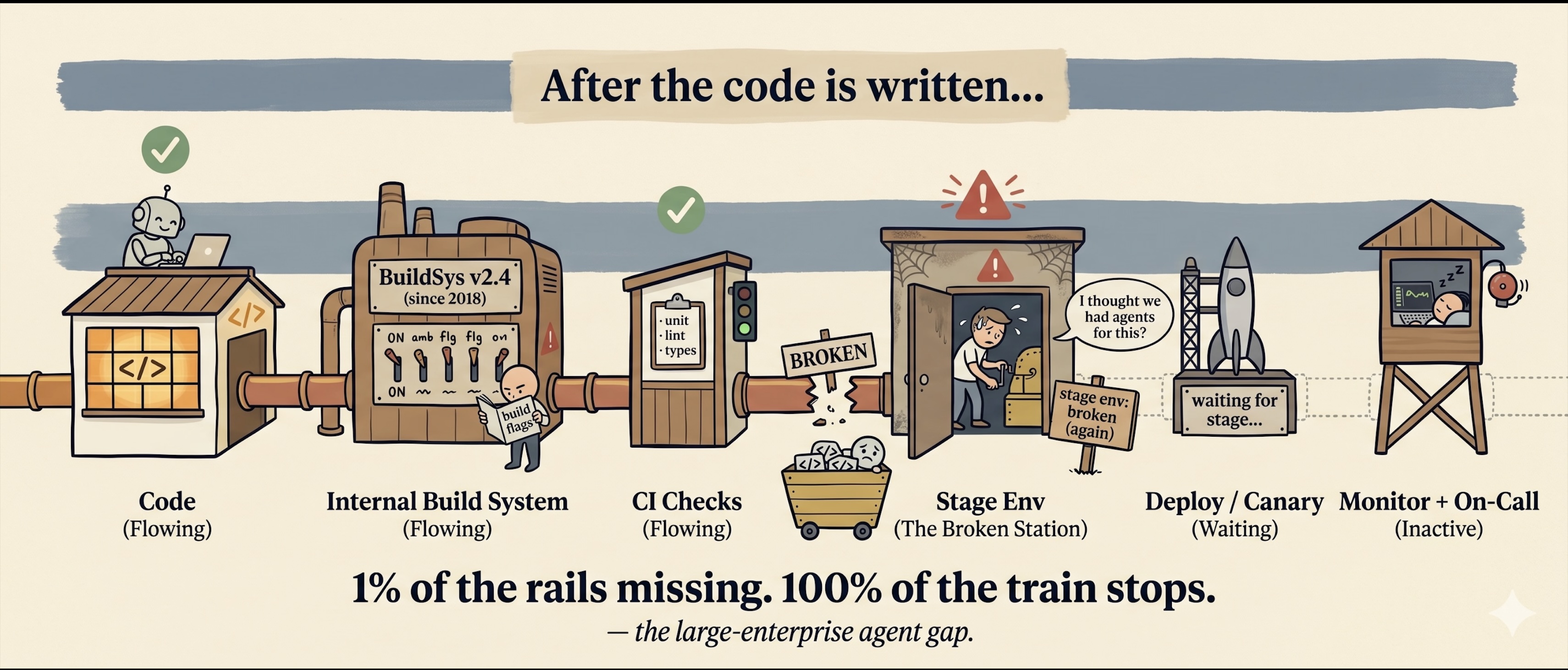
That points to a counter-intuitive conclusion most coverage misses: large enterprises are slower at agent adoption than startups. The conventional story (big company has resources, agents land faster) has the sign wrong. Sundar Pichai said internally that Google generates 30% of its code with AI. But Google built all thousand of those internal chains itself, so Google can afford to AI-ify each of them on schedule. A normal Fortune 500 has neither the muscle nor the budget to do the same to its 1990s-era inventory of internal CLIs. The agent walks two steps into the workflow and stops.
Second, fragmentation. MCP solved the calling convention. It did not solve what happens when the tool list explodes and the LLM gets lost in the catalog. Cloudflare’s September Code Mode post had the sharpest version of this:
“LLMs are better at writing code to call MCP, than at calling MCP directly.”
That’s a swing at MCP’s surface area, and also a real observation. Handed a pile of MCP servers, the model can’t navigate them. One server’s description can eat tens of thousands of tokens. Mount ten and the context window is gone before the task starts.
At a large company, going pure MCP means writing a server per platform. Data platform, ML training platform, internal search, monitoring, IAM, message queue. Mount them all and the agent has roughly no room left for the actual job.
Third, persistence. This is the most invisible of the three. A single agent has no memory across sessions. Every fresh Claude Code session starts at zero. A team’s tribal knowledge (which internal CLI flag does the thing, which table is canonical, which package mirror needs which proxy) has to be relearned every single time.
Harrison Chase’s April post Your harness, your memory put it cleanly:
“Without memory, your agents are easily replicable by anyone who has access to the same tools.”
No memory, no compounding. The traps I tripped on during onboarding a year ago, the agent will trip on today.
Coverage, fragmentation, persistence. Those three breaks are what the enterprise-execution last mile actually looks like up close.
So why are you still busy
Stack the previous four sections up and you get a single answer.
AI accelerates writing code, which is the thinnest slice of the workday. The 70% that keeps you at the screent sits in enterprise execution: fighting seven internal tools, waiting on training metrics, chasing a flaky e2e test in stage. Two years of evolution have pushed AI into the harness era. But the enterprise-execution last mile is still mostly closed off.
This is an organizational problem. The model is enough. Most companies’ internal infrastructure is not ready to receive the model.
What’s changed about your week is the shape. AI made one segment of the workflow 5x faster. The rest stayed manual. Before, slow but even. Now, the asymmetry is what hurts. You feel fast in the part you measure and slow in the part you don’t.
Next time someone tells you “AI just makes code a little faster, what’s the big deal,” you can tell them they’re measuring wrong. The first question is how far the workflow runs end to end. Then ask where the AI is.
Your won’t get your hours back from the next model. You’ll get them back from the next generation of workflow engineering.
So how do you build that workflow engineering? How do you keep a single agent on rails for 20 hours? How do you get multiple agents to collaborate seamlessly? How do you make your agent self-learning tribal knowledge from your company and memorize them? How do you make your agent working in a large company whose internal infra is not that AI-ready? In a nutshell, how do I make myself less busier? Those are the problems I’ve been trying to solve. I’ve been doing an experiment Superteam: a stack stitching together PM-style brainstorm, shell hard-gates, multi-agent pairing, tmux long-running sessions, and a local wiki. Next post will share my experience of replacing myself.