Take a photo of coins and get the total value of them

Author/Partipatant: Zejun Lin
Contributions:
- Collect dataset
- Code in this Notebook
- With a slide for presentation
Links:
- Dataset: https://drive.google.com/file/d/1oiifbiPnHtTpn20PShbPrFe_JV9oDGPK/view?usp=sharing
- Yolov4 code: https://github.com/Tianxiaomo/pytorch-YOLOv4
- PyTorch Weight File: https://drive.google.com/file/d/110o6tbu15qYIhNMhBQU_Qtefn02j9HDR/view?usp=sharing
- Presentation: https://drive.google.com/file/d/1vu0oqGmp6soOwozjmMCW26c8P2cdreSk/view?usp=sharing
Description
What it is
When I first came to the US, I found it really difficult to count coins because there are many types of them and it is difficult to identify those tiny things just by their similar appearance.
Therefore, given the opportunity, I decide to develop an intelligent system that can tell people the total value of a bunch of coins just by taking a photo.
Deep Learning Model
Yolov4 — PyTorch version
I decide to try Yolov4 first, which is the SOTA model for object detection. I treat each kind of coin as a class of object. Then given an image, I try to find all different kinds of coins by the model, then apply postprocessing like NMS to get the result. Finally, but counting the number of different class of objects in the images, I can multiple them with denominations of different kinds of coins and get the total value.
Yolo is the abbreviation of You Only Look Once, used for Unified, Real-Time Object Detection. It frames object detection as a regression problem to spatially separated bounding boxes and associated class probabilities. A single neural network predicts bounding boxes and class probabilities directly from full images in one evaluation. Since the whole detection pipeline is a single network, it can be optimized end-to-end directly on detection performance.
More information of Yolo please refer to https://arxiv.org/abs/1506.02640
I choose one of the PyTorch implementation on Github: https://github.com/Tianxiaomo/pytorch-YOLOv4
Hyper parameter
After trying repeatedly, I found that…
- Batch size should be small — I tried 32/16/8, etc. but not work — loss didn’t decrease
- Finally I decided to use 4 as the batch size
- Should optimize according to global step, so I set
subdivisionas 1 - Others:
- max_batches: 10000
- steps: [8000, 9000]
- width == height == 800
- Too large — out of memory
- Too small — underfit
- lr: 0.001
- This is fine as I use adam as optimize with a scheduler
- epoch: 600
Experiment
Dataset
Overview
I cannot find any coins dataset for object detection online. But I did find some pictures of coins. I also have some coins myself which I can take some photos of. So I will first utilize these photos, maybe do some transformation of them to get more raw data. Then I know there is some tools online for me to label them manually. The label for object detection is usually like:
- x1, y1, x2, y2, class_id
where, x1, y1, x2, y2 represents a bounding box.
Usually a input image has some bounding-box labels like this. By using the tool I can label the data.
For the test set, it’s pretty easy, that I just need to count coins with weight as their denominations and get the total value. A possible evalution method would be the accuracy.
Preprocessing
- I use a tool called labelImg, which can be install by
python3 -m pip install labelImg. - However, the output format is like (x_mid, y_mid, width, height class_id) (dtype = float as the % of width & height)
- So two preprocessing should be done:
- Transform to (x_min, y_min, x_max, y_max, class_id)
- Transform the unit from percentage to actual pixel
- Another one is that because I use IPhone to take these pictures and move to OS X by airdrop, the format of them is
HEIC, that I need to convert tojpg.
Download
Available on https://drive.google.com/file/d/1oiifbiPnHtTpn20PShbPrFe_JV9oDGPK/view?usp=sharing
1 | import os |
1 | from wand.image import Image |
1 | root = "/Users/danny/Desktop/coins" |
1 | import cv2 |
1 | convert2yolo_format(root) |
Done
Training
1 | from matplotlib import pyplot as plt |
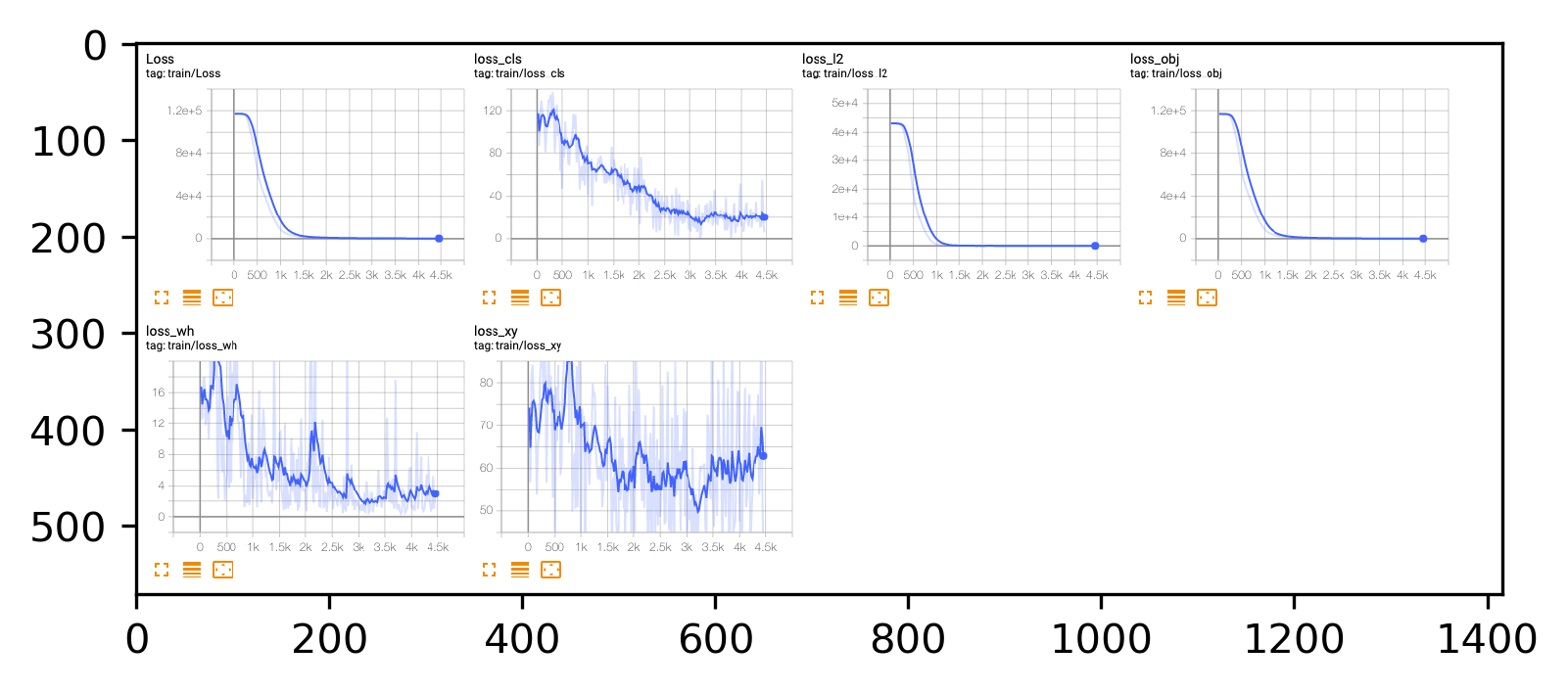
Loss
1 | show_img('loss.png') |
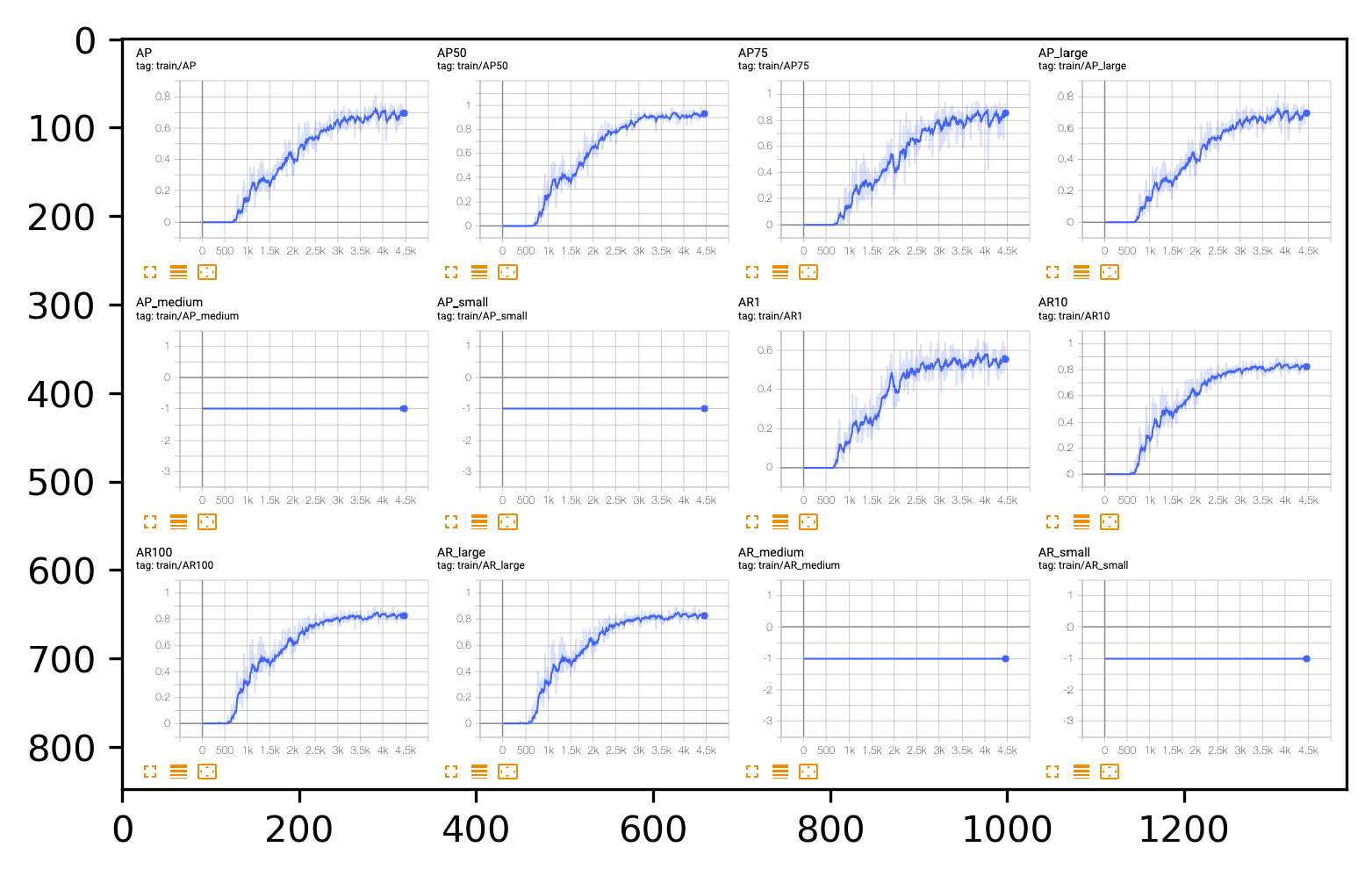
Avg Precision & Avg Recall
1 | show_img('apac.png') |
Model Selection
According to the figure by tensorboard, I selected Yolov4_epoch411 as the final model and the result looks good.
Inference
Global variables
1 | import os |
1 | %matplotlib inline |
1 | from models import * |
1 | weight_file = "Yolov4_epoch411.pth" |
Predict, Plot BBox & Get total values
1 | count_and_plot("data/imgs/IMG_4755.jpeg", model) |
-----------------------------------
Preprocess : 0.045525
Model Inference : 0.234886
-----------------------------------
-----------------------------------
max and argmax : 0.011173
nms : 0.002164
Post processing total : 0.013337
-----------------------------------
There are:
3 25 cent(s) coins;
1 5 cent(s) coins;
1 100 cent(s) coins;
2 1 cent(s) coins;
3 10 cent(s) coins;
Totally: 212 cents
1 | count_and_plot("data/imgs/IMG_4766.jpeg", model) |
-----------------------------------
Preprocess : 0.024374
Model Inference : 0.094530
-----------------------------------
-----------------------------------
max and argmax : 0.008022
nms : 0.001669
Post processing total : 0.009692
-----------------------------------
There are:
3 25 cent(s) coins;
1 5 cent(s) coins;
1 100 cent(s) coins;
3 1 cent(s) coins;
3 10 cent(s) coins;
Totally: 213 cents

Some problems I came across
- Library used by Python Kernel is not the same as the one in shell, which cause
load_weightfail. - Cannot use cv2.imshow & cv2.retangle on remote Jupyter notebook due to QT module missing.